
Design Architectures for Distributed Systems
Subtitle: A Guide to Designing Architectures in Distributed Systems


This Article talks about architectural design for distributed systems including styles, client-server architecture & decentralized peer-to-peer.
Major factors that affect distributed systems are what are these devices, how they communicate(modes of communications like socket and RPC remote Procedure calls) & what roles and responsibilities they hold.
Based on the capacity and need various architectures could be followed.
Layered architectures: Think of it as there being n layers in a large architecture, with requests and responses flowing through these layers. Each layer relies on the previous layer to implement new functionality and is responsible for providing services to the layer above. Multi-tier web apps use these kinds of mechanisms. Complex systems are partitioned into layers, where upper layers rely on services from lower layers, essentially creating a vertical organization of services. A few advantages of this approach include a simplified design for complex distributed systems by concealing the underlying layers, making only the top layers visible. Requests and responses flow from layer to layer.
Distributed system can be divided into 3 layers:
Platform:
It has OS & computing and networking hardware. It includes low-level hardware and software layers & provides common services for higher layers.
Middleware:
Masks the diversity of underlying models and provides suitable programming models to the developers. Simplifies the application programming by abstracting communication mechanisms
Applications: It has the top level applications
Object-based architectures:
Each component is an object; they interact with each other by method calls or RPC. Ex: Client-server architecture.
RPC (Remote Procedure Call):
RPC is a high-level communication mechanism that abstracts network communication and allows a program to execute procedures or functions on a remote machine as if they were local.
With RPC, a program can make a function call to a remote server and receive the result, just as if the function were a local function.
RPC systems handle the marshaling (packing data into a format suitable for transmission) and unmarshalling (unpacking data on the receiving end) of data, making remote calls transparent to the developer.
RPC is often used in distributed systems and for building distributed applications where different parts of the program run on separate machines and need to communicate.
Data-centered architectures or Cloud architecture
Event-based architectures
Communications via common repository. It uses a publisher & subscriber-based architecture or observer model to be specific in Software engineering lang. consumers are subscribers to events, publisher notify the subscriber once the event happens.

Resource-based architectures
REST (Representational State Transfer) Client -> req(JSON) -> HTTP methods -> Server -< sends back a response(JSON). It is the base for Restful web services, Resources are identified and interacted with a URI (Uniform Resource Identifier). The interface is common ie; GET< POST< DELETE< POST etc. It follows stateless execution, no caller state is maintained or stored.
Shared data space / Bulletin-board Architecture:
It has a shared/persistent database, and components interact with this shared memory for fetching and publishing changes. Posted items in the shared space could be fetched by consumers later.
Client-Sever Architecture:
The client sends a request and waits for the server's response; there is time coupling in this process. The whole application layer is divided into the UI layer, processing, and data levels.
High level of Search engine Architecture

Tiering:
Organize the functionality of a service step by step and place the functionality into appropriate servers or places. It is a physical structuring mechanism for the system infrastructure.
Ex: A ticket booking app, Show UI -> Get Input from customers -> Fetch data from database -> Rank the offers and fares -> Display result to cx.
The Above Can be represented into multiple tiers like 2 tier, 3 tier. The most common is the 3 tier representation where:
Tier 1 -> Display user input screen/ Display result to user { Presentation Logic}
Tier 2 -> Get user Input / Rank the offers { Application Logic }
Tier3 -> Database { Data Logic }
The server uses a client-server architecture in the 3-tier web applications; constantly interacts with the Application server while time is not coupled and moves ahead through the process (which means request and response takes time) and is quite common in web-based applications.
Advantages:
• Enhanced maintainability of the software (one-to-one mapping from logical elements to physical servers) • Each tier has a well-defined role
Disadvantages:
• Added complexity due to managing multiple servers • Added network traffic • Added latency
Edge - Server System:

client-server arch changed to client-proxy-server arch.
Content distribution networks: proxies cache web content from content providers near the edge, basically making the request and response stream fast and also for smooth streaming of the contents.
Decentralized peer-to-peer arch:
This architecture suggests that all nodes are equally important and there is no hierarchy; this avoids a single point of failure, making the system fault-tolerant. There is no central coordinator for coordinating tasks, which in turn makes decision-making harder. The underlying system can scale indefinitely, allowing the system to avoid performance bottlenecks. Peer-to-peer systems remove any distinction between client and server and are spread across a network of nodes. Chord is a structured peer-to-peer system that uses a distributed hashtable to locate nodes/objects. Data items are associated with key k, where the smallest node is always >= k.
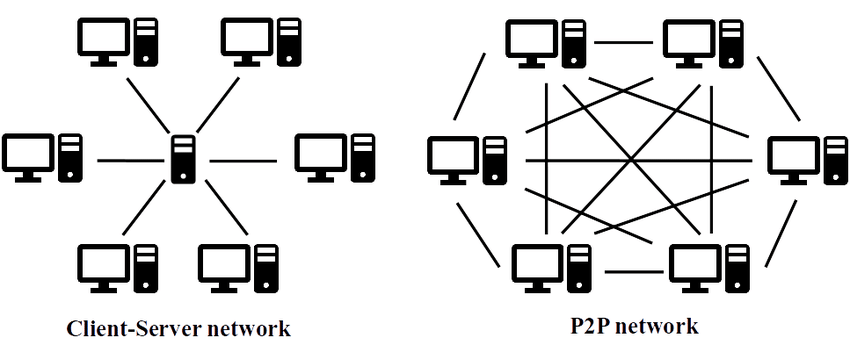
P2P Architecture:
peers can interact & share data directly or form groups offering services to each other. Always minimum of 1 peer should send data and the peer should be accessible. Popular data will be more available than unpopular data which eventually fades/unavailable cause no one's sharing it.
peers can make their virtual spread across the network on top of a physical network topology & each peer plays a role in routing traffic over that network.
Collaborative Distributed Systems / Bit Torrent:

Collaborative P2P downloads: It is downlaoding chunks of files from multiple peers more the seedes the better; then finally reassembling the chunks as a whole. It uses a global directory like Pirate Bay which has .torrent files in the file server, this file has ref to the requested File**.** It has ref to a tracker ( a server that maintains the info of active nodes seeding that requested chunk or File ). It follows a mechanism of Force altruism which means if a Peer sees that another peer Q downloads more than uploads it reduces the rate of sending to the Q.
Types of P2P architecture:
Structured: Folows a structure network overlay or spread network. Peers and contents are tightly coupled mostly by hashing, making it easier to locate data.
A few disadvantages are that it is hard to build. For optimized data location, peers must maintain extra metadata (e.g., lists of neighbors that satisfy specific criteria) and it is less robust against high rates of churn
Unstructured: follows no structured network spread. Each node picks a random set of nodes and becomes their neighbors. The network dynamics can be affected by the degree of choice.
Advantage:
Easy to build
Highly robust and high rate of churns ( when a large no of peers frequently join and leave the network)
Disadvantage:
- here peers and contents are loosely coupled which makes it hard to locate data. Searching for specific data may require broadcasting {broadcasting to whoever is there in the network}.
- Hybrid: For example, Napster; where there is a common directory node to which everyone connects. An extra central server is brought into the picture to help peers locate each other. It is a combination of P2P and master-slave models, essentially providing a trade-off between the centralized functionality provided by the master-slave model and node equality provided by the P2P model. It combines the advantages of the master-slave architecture and prevents their disadvantages.
Self-Managing Systems:
These are self-managing systems that monitor themselves and take actions independently when needed. keywords: Autonomic/Autonomous computing, self-managing systems, self-managing, self-healing. Example: The auto scale of cloud services; automatic capacity provisioning. Monitors workload on the server and computes the current and future demand and based on that adjusts resource allocation. These use a feedback and control theory to design a self-managing system.