EMR with EKS

Hi, welcome to the event! Amazon EMR is like the Rockstar of cloud big data. Picture this: petabyte-scale data parties, interactive analytics shindigs, and even machine learning raves—all happening with cool open-source crews like Apache Spark, Apache Hive, and Presto.
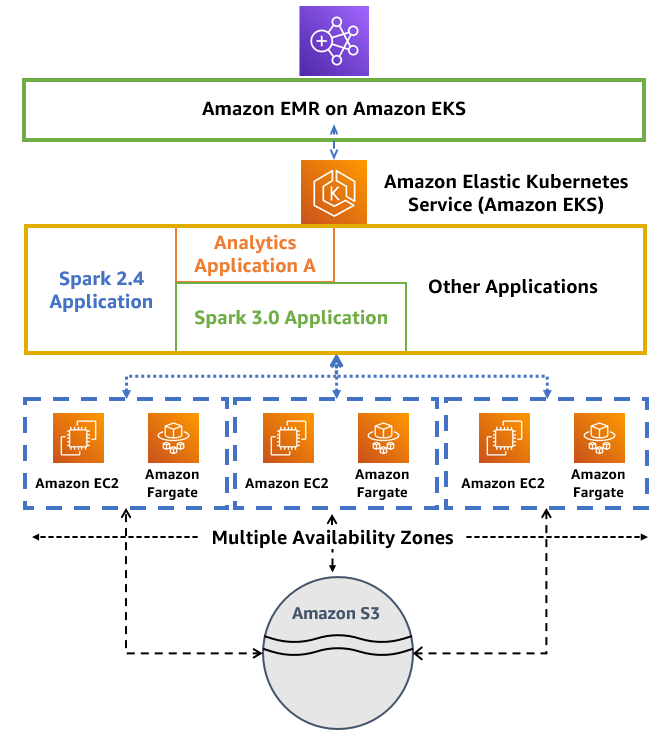
Now, let's talk about the real showstopper—> EMR on EKS. It's the background magic trick automating the setup and vibe management of those big data crews on EKS. Why bother? Well, running Spark with EMR on EKS is like turbo mode
💪3x faster, fully managed, and with cool perks like built-in monitoring and logging. It's like having a single pass to orchestra that seamlessly grooves with Kubernetes and trust me, it's a game-changer.
Your Spark jobs? Bam executed! Deployed in seconds, leaving those old-school EC2 deployments in the dust. It's like upgrading from copper cables to fiber optics; which means speed! 🚀🎸
Data & Big Data in simple kid-friendly language
Imagine you have a super cool box where you keep all your toys, drawings, and maybe even some secret superhero plans. Now, think of each of these things inside the box as data which are 📚 just fancy bits of information.
Now, let's talk about "Big Data." It's like having not just one, but a gazillion of these super cool boxes 📦, each filled with tons and tons of toys, drawings, and superhero plans. Big Data is when you have so much information that it's like trying to count all the stars in the sky => Can you do that?!
So, imagine you have a magical wand, and you want to learn cool things by waving the wand at all these boxes. Big Data is like having a bunch of wizards and magical creatures helping you make sense of everything inside those boxes. It's not just data; it's a whole adventure of discovering and understanding lots and lots of fascinating things! 🌟📦✨
EMR (Elastic MapReduce):
- "EMR" stands for "Everyday Magical Rainbows" kidding = Elastic MapReduce Is a wizard helping you process gigantic amounts of data. So, think of it as a tool which helps manage, process, query and act on the Big Data!"
EKS (Elastic Kubernetes Service):
- "EKS" is short for "Epic Kitten Swirls" kidding= AWS'sElastic Kubernetes Service, Imagine a swirl of adorable kittens managing your computer stuff—it's like having a team of fluffy superheroes running the show, the can call their friends and increase their group size whenever they want and they all play together. So, EKS is all about kittens, making your life easy!"
There you have it, a touch of relief in the tech world! 🌈🦄🐾
LETS START THE PLAY:
I assume, you have a working EKS cluster setup already, if not check this blog.
Lets start, creating a namespace and giving it special powers, (RBAC) is like setting up a VIP zone in tech land. Using eksctl, our automation whiz, we breeze through this process, granting our namespace exclusive access.
Now, we're not stopping there. We're also ensuring EMR on EKS gets the royal treatment by adding its service-linked role into aws-auth configmap. It's like giving a VIP guest the keys to all the tech rooms.
In short, eksctl is our automation go-to, RBAC empowers our namespace, and EMR on EKS gets the VIP pass in aws-auth configmap. 🚀
Enable IAM Roles for Service Accounts (IRSA) on the EKS cluster, you can get the cluster name by
$ eksctl get cluster
Enable IAM Roles for Service Accounts (IRSA)
But if you have read the previous article, then OpenId Connect (OIDC) is already configured.
eksctl utils associate-iam-oidc-provider --cluster <CLUSTER-NAME> --approve
# Create a namespace on EKS for EMR cluster
> kubectl create namespace emr-weds-eks
#Enable Amazon EMR in EKS emr-eks-workshop-namespace namespace
> eksctl create iamidentitymapping \
--cluster <CLUSTERNAME> \
--namespace emr-eks \
--service-name "emr-containers"
Create Amazon EMR in EKS virtual cluster in emr-weds-eks namespace. Register the Amazon EKS cluster with Amazon EMR
aws emr-containers create-virtual-cluster \
--name emr_eks_cluster \
--container-provider '{
"id": "CLUSTER-NAME",
"type": "EKS",
"info": {
"eksInfo": {
"namespace": "emr-weds-eks"
}
}
}'
Create IAM Role for job execution:
create the role that EMR will use for job execution. This is the role, EMR jobs will assume when they run on EKS.
> touch emrJobAccessRole.json
> vim emrJobAccessRole.json # 😎 add the below code in this file
# 😥 Don't be worried, you can do the above using any text editor😎
------------------------------------------------------------------------
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket"
],
"Resource": ""
},
{
"Effect": "Allow",
"Action": [
"logs:PutLogEvents",
"logs:CreateLogStream",
"logs:DescribeLogGroups",
"logs:DescribeLogStreams"
],
"Resource": [
"arn:aws:logs:::"
]
}
]
}
EMR jobs will refer this role when they run on EKS.
aws iam put-role-policy \
--role-name emrJobAccessRole \
--policy-name emrJobAccess \
--policy-document < path to emrJobAccessRole.json >
Setup the Trust Policy for the IAM Job Execution Role in emr-weds-eks namespace
aws emr-containers update-role-trust-policy \
--cluster-name <CLUSTER-NAME> \
--namespace emr-weds-eks \
--role-name emrJobAccessRole
** Here is the chance to integrate AWS Fargate on Amazon EKS, you can do it before aswell, but here you can configure it
Little Background on Fargate!
AWS Fargate with Amazon EKS is like having your own team of efficient waitstaff at a fancy restaurant. Let me break it down:
Amazon EKS (Elastic Kubernetes Service): Think of EKS as the fancy restaurant itself. It's the place where you orchestrate and manage your containers. Just like a restaurant has chefs preparing dishes, EKS ensures your containers are well-managed and coordinated.
AWS Fargate: Now, Fargate is like having a team of excellent servers management at the restaurant 😋. Instead of you worrying about hiring and managing servers (waitstaff), Fargate takes care of it for you. You tell Fargate what containers you want, and it handles all the background work—like taking orders from EKS (the kitchen) and delivering your containers to the tables (where they need to run).
In simpler terms, with Fargate and EKS together, you get all the benefits of a out of the world restaurant experience without having to worry about the management load. It's like having a smooth, hassle-free dining experience in the world of containers and cloud computing! 🍽️✨
Only if you want! (OPTIONAL)
Enable Amazon EMR in EKS eks-fargate namespace , of course this namespace needs to be created first.
> kubectl create namespace emr-weds-eks-venue-fargate
eksctl create iamidentitymapping \
--cluster <CLUSTER-NAME> \
--namespace emr-weds-eks-venue-fargate \
--service-name "emr-containers"
Setup the Trust Policy for the IAM Job Execution Role in emr-weds-eks-venue-fargate namespace
aws emr-containers update-role-trust-policy \
--cluster-name <CLUSTER-NAME> \
--namespace emr-weds-eks-venue-fargate\
--role-name emrJobAccessRole
Finally!
Check your EMR on EKS cluster by running the command below. Note the id of your EMR cluster. We will use that for submitting jobs to the EMR cluster.
aws emr-containers list-virtual-clusters
But I love AWS console 😒**:** Go to AWS Console -> Services -> EMR -> Virtual Clusters to verify your EMR cluster
Submit Spark Jobs:
Before this add your spark script somewhere, but where! Taddaaa! S3 Bucket..
S3 Bucket in simple kid-friendly language
Imagine S3 bucket is like a special magical toy box in the cloud/internet. Now, instead of toys, this magical bucket keeps all kinds of digital stuff; pictures, videos, and even songs. And guess what? You can put things in the bucket or take them out whenever you want, no matter where you are. It's like having your toy box with you wherever you go always ready to play! The best part? This magical bucket is super safe, so all your digital treasures are protected and can be shared with your friends or kept just for you. ☁️🪣🚀 Just one thing, 😁 be creative and give a unique name to your Bucket, cause you have to be unique to make your toy box the exciting one.
Go to AWS search > S3 > On S3 window > click 'Create bucket,' specifying a unique name and region, configuring optional settings, and hitting 'Create bucket'. VOLAA !! 🐱🏍
Upload your spark script in the bucket ! Let my bucket name is myscriptboxand inside that I created a folder called scripts
I will demonstrate this using a simple script of python which uses pyspark to find the value of [Pi ](https://en.wikipedia.org/wiki/Pi#:~:text=The%20number%20%CF%80%20(%2Fpa%C9%AA,diameter%2C%20approximately%20equal%20to%203.14159.) . Copy the below script and paste in >
Pi.pyfile 🤔you can give any name you want. Place this inside the scripts folder 🐱👤
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_: int) -> float:
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
Few Good Practices, Set Environment variables rather making your own queries complicated!
export EMR_EKS_CLUSTER_ID=<virtual-cluster-id>
# paste the Jobrole arn below👀always recommended to copy directly from console
export EMR_EKS_EXECUTION_ARN="AWS ID":role/emrJobAccessRole\
export S3_BUCKET=<S3Bucket>
Lets start the execution!
aws emr-containers start-job-run \
--virtual-cluster-id EMR_EKS_CLUSTER_ID \
--name <name your spark Job> \
--execution-role-arn EMR_EKS_EXECUTION_ARN \
--release-label emr-6.2.0-latest \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "s3://myscriptbox/scripts/pi.py",
"sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1"
}
}'
sparkSubmitParameters is fully customizable read more here.
But How you will see the execution outputs ? Cause don't expect it will give you the spark execution logs on the shell. So for solving this cosmic challenge, we can use the monitoring tool in AWS called Cloudwatch.
Cloudwatch in simple kid-friendly language
Your bud CloudWatch is like a friendly superhero that keeps an eye on all the computers and programs in the cloud. Just like how superheroes have special powers, CloudWatch has the power to watch, listen, and check if everything is working perfectly. So, if there's a computer acting a bit funny or a program that needs a little help, CloudWatch is the Bud who informs you; very loyal. ☁️👀✨
Well let's integrate CloudWatch for monitoring & know exactly what the heck is going on. VERY VERY EASY ! 😎
Steps:
Open AWS Console:
Navigate to CloudWatch: Search "CloudWatch" and select the CloudWatch service.
Access Logs: In the CloudWatch dashboard, locate the "Logs" section in the left-hand navigation pane.
Create Log Group: Click on "Log groups" and then click the "Create log group" button > Enter your desired Log Group Name (e.g., "emr_eks_group") and click "Create log group."
Create Log Stream: Within the Log Group you just created, click on "Create log stream." Enter the desired Log Stream Name Prefix (e.g., "emr_eks_stream"), then click "Start streaming." 🏄♀️
Well the CloudWatch setup is done! Easy ain't it ?
Let's execute the command now.
aws emr-containers start-job-run \
--virtual-cluster-id EMR_EKS_CLUSTER_ID \
--name <name your spark Job> \
--execution-role-arn EMR_EKS_EXECUTION_ARN \
--release-label emr-6.2.0-latest \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": "s3://myscriptbox/scripts/pi.py",
"sparkSubmitParameters": "--conf spark.executor.instances=2 --conf spark.executor.memory=1G --conf spark.executor.cores=1 --conf spark.driver.cores=1"
}
}' \
--configuration-overrides '{
"monitoringConfiguration": {
"cloudWatchMonitoringConfiguration": {
"logGroupName": "emr_eks_group",
"logStreamNamePrefix": "emr_eks_stream"
}
}
}'
Now do to the CloudWatch log stream and there you will see all the logs and finally the mysterious value of Pi π . 🤗
That's all for today au revoir. 😊



